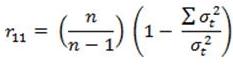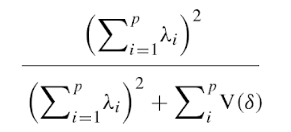1 Validity
2 Determining Validity
There are several ways to measure validity. The most commonly addressed include:- Face Validity- Construct & Content Validity- Convergent & Divergent Validity- Predictive Validity- Discriminant Validity
3 Validity Refers to measuring what we intend to measure.
If math and vocabulary truly represent intelligence then a math and vocabulary test might be said to have high validity when used as a measure of intelligence.
4 Face Validity Is the extent to which it is self-evident that a scale is measuring what it is suppose to measure.For Example – you might look at a measure of math ability, read through the questions, and decide that yep, it seems like this is a good measure of math abilityIt would clearly be weak evidence because it is essentially a subjective judgment call. Just because it is weak evidence doesn’t mean that it is wrong. We need to rely on our subjective judgment throughout the research process.For example- suppose you were taking an instrument reportedly measuring your attractiveness, but the questions were asking you to identify the correctly spelled word in each list. Not much of a link between the claim of what it is supposed to do and what it actually does.
5 Face Validity (cont.)The question is not whether it is measuring what it is supposed to measure, but whether it appears to measure what it is supposed to be measuring.Face validity is important for some tests. If examinees are not interested or do not see the relevance of a particular test, they may not take it seriously or participate to the best of their abilities.
6 Face Validity (cont.)In all cases, face validity is not based on empirical research evidence.When used alone, face validity provides very weak support for the overall validity of a scale.We can improve the quality of face validity assessment considerably by making it more systematic. For instance, if you are trying to assess the face validity of a math ability measure, it would be more convincing if you sent the test to a carefully selected sample of experts on math ability testing and they all reported back with the judgment that your measure appears to be a good measure of math ability.
7 Face Validity (cont.) Possible Advantage of face validity…
If the respondent knows what information we are looking for, they can use that “context” to help interpret the questions and provide more useful, accurate answers.Possible Disadvantage of face validity…If the respondent knows what information we are looking for, they might try to “bend & shape” their answers to what they think we want.i.e., “fake good” or “fake bad”
8 Content ValidityDoes the test contain items from the desired “content domain”?Based on assessment by experts in that content domain.Is especially important when a test is designed to have low face validity.Is generally simpler for “other tests” than for “psychological constructs”For Example – Easier for math experts to agree on an item for an algebra test than it is for psych experts to agree whether or not an item should be placed in a EI or a personality measure.Content Validity is not “tested for”. Rather it is assured by experts in the domain.
9 Content Validity (cont.)
Basic Procedure for Assessing Content Validity:1. Describe the content domain2. Determine the areas of the content domain that are measured by each test item3. Compare the structure of the test with the structure of the content domainFor Example – In developing a nursing licensure exam, experts on the field of nursing would identify the information and issues required to be an effective nurse and then choose (or rate) items that represent those areas of information and skills.
10 Content Validity (cont.)
Lawshe (1975) proposed that each rater should respond to the following question for each item in content validity:Is the skill or knowledge measured by this item1. Essential2. Useful but not essential3. Not necessaryFor Example – With respect to educational achievement tests a test is considered content valid when the proportion of the material covered in the test approximates the proportion of material covered in the course.
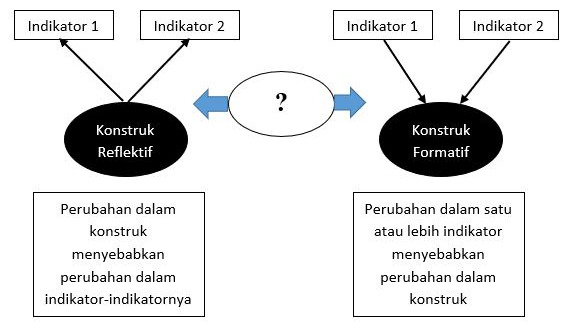
11 Construct ValidityConstruct Validity basically refers to the general validity of the measurement tool.Does the instrument measure the construct that it is intended to measure?There is no statistical test that will provide an absolute measure for construct validity. Therefore, construct validity is never proven, it can only be supported.
12 ConstructsAre ideas that help summarize a group of related phenomenon or objects.All constructs have 2 essential properties:1. Are abstract summaries of some regularity in nature.2. Related with concrete, observable entities.For Example – Integrity is a construct; it cannot be directly observed, yet it is useful for understanding, describing, and predicting human behaviour.
13 Operational Definitions
An operational definition is a formula (recipe) for building a construct in a way that other scientists can duplicate.e.g. Depression is defined by concepts of the DSM IV, Intelligence is defined by a specified test made up of logical relationships, short term memory, word associations.The definition must be clear.Must allow people to apply it.One problem with operational definitions – if we don’t like the operational definition, there is nothing to prevent us from giving the variable another one.
14 Psychological Constructs
Psychological measurement is a process based on concrete, observable behaviour.Construct Explication – process of providing a detailed description of the relationship between specific behaviors and abstract constructs. This process consists of 3 steps:1. Identify behaviours related to the construct.2. Identify other constructs and decide whether they are related or unrelated to the construct being measured.3. Identify behaviours that are related to the additional constructs & determine if these are related or unrelated to the construct being measured. (Example p. 157)
15 Construct ValidityThink of a construct as something that is like an idea or mental map that we are trying to understand.For example – intuition is a construct. There is no place on the brain (as of yet) that can be identified as Intuition. But we see lots of behaviors that seem to be expressions of some quality we call Intuition. Is there evidence for the claim that the construct is real and operates in our life?So, to test certain constructs we have to collect lots of evidence. Usually, the evidence is collected by correlating the instrument in question with lots of other instruments thought to measure a similar thing and with some that say they don’t measure the same thing.
16 Construct Validity (cont.)
Attention to construct validity reminds us that our defense of the constructs we create is really based on the “whole package” of how the measures of different constructs relate to each other.So construct validity “begins” with content validity (are these the right type of items) and then adds the question, “does this test relate as it should to other tests of similar and different constructs?
17 Measuring Construct Validity
Construct Validity involves comparing a new measure to an existing, valid measure.Usually existing valid measures don’t exist. That is often why the new scale is being created in the first place.Sometimes, however, a valid measure will exist but a new scale is being created that will have some advantage over the older measure More up-to-date with current theory Shorter A new alternative measure
18 Discriminant Validity
The statistical assessment of Construct Validity…Does the instrument show the “right” pattern of interrelationships with other instruments.e.g., It would be expected that individuals diagnosed with clinicaldepression would score significantly worse on a valid depression scalethan would individuals who received no such diagnosis.Discriminant Validity has two parts:Convergent ValidityDivergent Validity
19 Convergent & Divergent Validity
Convergent Validity: the extent to which the scale correlates with measures of the same or related concepts e.g., A new scale to measure Assertiveness should correlate with existing measures of Assertiveness, and with existing measures of related concepts like Independence.Divergent Validity: the extent to which does not correlate with measures of unrelated or distinct concepts e.g., An assertiveness scale should not correlate with measures of aggressiveness.
20 A Test Must Be Valid – Discriminant Validity
Test-to-test correlations can range from 0.0 to near 1.0.r = .00 to .25 unrelated to minimally relatedr = .25 to .50 minimal to moderate overlapr = .50 to .75 moderate to high overlapr = .75 and highly overlapping to equivalent…even tests that are highly overlapping-to-equivalent may have subtle differences that are of theoretical interest (especially at the lower ranges).- from the MSCEIT Manual
21 Multitrait-Multimethod Matrix
The multitrait-multimethod (MTMM) matrix [Campbell & Fiske (1959)] is one of the methods used to assess a test’s construct validity.It is a matrix of correlation coefficients and provides information on convergent and divergent validity.Uses a number of different methods to measure more than one construct (e.g., observations, surveys, rating scales).For Example – Graph on pg. 163 of textbook
22 Criterion-Related Validity
A criteria is a measure that could be used to determine the accuracy of a decision.Criterion-related validity indicates the degree of the relationship between the predictor (the test) and a criterion (level of performance the test is trying to predict). e MSCEIT ManualThe predictor is a tool that is used to predict the criterion.
23 Criterion-Related Validity (cont.)
This type of validity measures the relationship between the predictor and the criterion, and the accuracy with which the predictor is able to predict performance on the criterion.For our example, the company psychologist would measure the job performance of the new artists after they have been on-the-job for 6 months. He or she would then correlate scores on each predictor with job performance scores to determine which one is the best predictor.
24 Criterion-Related Validity (cont.)
HOW THIS TYPE IS ESTABLISHED: Criterion-related validity can be either concurrent or predictive. The distinguishing factor is the time when criterion and predictor data are collected.Concurrent – criterion data are collected before or at the same time that the predictor is administered.Predictive – criterion data are collected after the predictor is administered. Manual
25 Concurrent ValidityThis type of validity indicates the correlation between the predictor and criterion when data on both were collected at around the same time.Is used to determine a person’s current status.For Example – to assess the validity of a diagnostic screening test. In this case the predictor (X) is the test and the criterion (Y) is the clinical diagnosis. When the correlation is large this means that the predictor is useful as a diagnostic tool.Concurrent validity are practical, easy to conduct, test scores are obtained immediately if needed.
26 Predictive ValidityThis type of validity also indicates the correlation between the predictor (X) and the criterion (Y). However, criterion data are collected after predictor data are obtained. In other words, this method determines the degree, that X can accurately predict YFor Example – giving high school juniors the ACT test for admission to a university.The test is the predictor and first semester grades in college are the criterion. If the correlation is large, this means the ACT is useful for predicting future grades.
27 Predictive Validity (cont.)
The extent to which scores on the scale are related to, and predictive of, some future outcome that is of practical utility.e.g., If higher scores on the SAT are positively correlated withhigher G.P.A.’s and visa versa, then the SAT is said tohave predictive validity.The Predictive Validity of the SAT is mildly supported by the relation of that scale with performance in graduate school.
28 Predictive ValidityA predictive validity study consists of two basic steps:1. Obtain test scores from a group of respondents, but do not use the test in making a decision.2. At some later time, obtain a performance measure for those respondents, and correlate these measures with test scores to obtain predictive validity.
29 Examples of Predictive Validity
For instance, we might theorize that a measure of math ability should be able to predict how well a person will do in an engineering-based profession.We could give our measure to experienced engineers and see if there is a high correlation between scores on the measure and their salaries as engineers.A high correlation would provide evidence for predictive validity — it would show that our measure can correctly predict something that we theoretically thing it should be able to predict.
30 A Test Must Be Valid – Predictive Validity
When evaluating test to real-life predictions, even very modest correlations of r = .02 or .03 can be of considerable importance. For example, the impact of chemotherapy on breast cancer survival is r = .03.In selection, hiring, and counseling contexts, current interpretations suggest that correlations as low as r = .02 or .03 are meaningful, with many psychological (and medical test) assessments and real life criteria falling in the r = .10 to .30 level, and a few rising beyond that level.- from the MSCEIT Manual
31 FACTORS THAT INFLUENCE VALIDITY
Inadequate sampleItems that do not function as intendedImproper arrangement/unclear directionsToo few items for interpretationImproper test administrationScoring that is subjective
32 Meta-AnalysisRefers to the method for combining research results from large number of studies. Especially in studies where conflicting findings abound.Rarely do large numbers of studies use precisely the same tests and criterion measures, and it is necessary to make judgements about which studies should be grouped together.AdvantagesGives an overall estimate of validity – especially helpful with predictive validity studiesMore definitive than the traditional ways of conducting literature review.Larger sample sizes
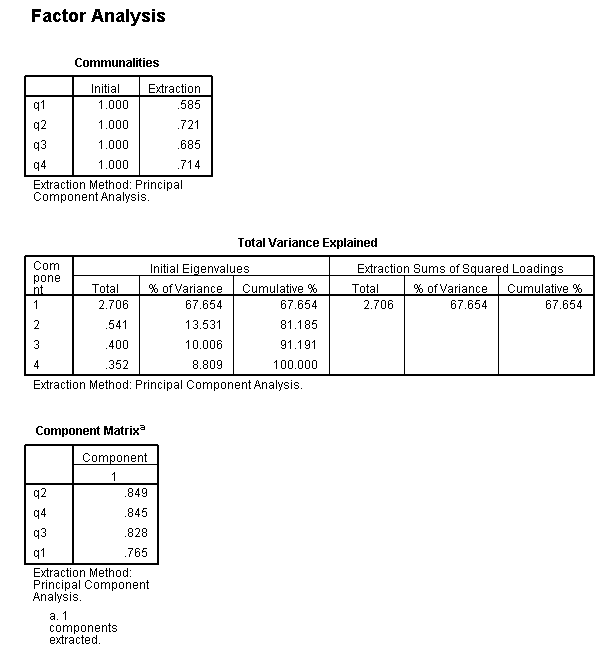
33 Factor AnalysisA factor is a combination of variables that are intercorrelated and thus measure the same characteristicIs a statistical technique used to analyze patterns of correlations among different measures.- MSCEIT ManualThe principal goal of factor analysis is to reduce the numbers of dimensions needed to describe data derived from a large number of data.It is accomplished by a series of mathematical calculations, designed to extract patterns of intercorrelations among a set of variables.Not all constructs have underlying factors
34 Factor Analysis The two most commonly used Factor Analysis Methods:
Exploratory Factor Analysis – typically entails estimating, or extracting factors; deciding how many factors to retain. Is a statistical technique used to analyze patterns of correlations among different measures.Confirmatory Factor Analysis – a factor structure is tested for its fit (e.g., goodness of fit).- MSCEIT Manual
35 Factor Analysis Possible Advantages Simplifies interpretation
Can learn more about the composition of variablesPossible DisadvantagesDo the combining of factors capture the essential aspects of what is being measured?Are the factors generalizable to other populations (e.g., different cultures, gender, individuals with disabilities
36 RELIABILITY AND VALIDITY
RELATIONSHIP BETWEENRELIABILITY AND VALIDITYReliability means nothing when the problem is Validity.
37 Relationship Between Reliability & Validity
Reliability and validity are two different standards used to gage the usefulness of a test. Though different, they work together.It would not be beneficial to design a test with good reliability that did not measure what it was intended to measure. The inverse, accurately measuring what you desire to measure with a test that is so flawed that results are not reproducible, is impossible.Reliability is a necessary requirement for validity. This means that you have to have good reliability in order to have validity. Reliability actually puts a cap or limit on validity, and if a test is not reliable, it can not be valid.- from the MSCEIT Manual
38 Relationship Between Reliability & Validity
Establishing good reliability is only the first part of establishing validity.Validity has to be established separately. Having good reliability does not mean you have good validity, it just means you are measuring something consistently.Now you must establish what it is that you are measuring consistently. The main point here is reliability is necessary but not sufficient for validity.
39 Relationship Between Reliability & Validity
Tests that are reliable are not necessarily valid or predictive.If the reliability of a psychological measure increases, the validity of the measure is also expected to increase.- from the MSCEIT Manual
source : https://slideplayer.com/slide/5809201/